You've reached the internet home of Chris Sells, who has a long history as a contributing member of the Windows developer community. He enjoys long walks on the beach and various computer technologies.
Saturday, Dec 11, 2010, 5:57 PM
Fluent-Style Programming in JavaScript
I’ve been playing around with JavaScript a great deal lately and trying to find my way. I last programmed JS seriously about 10 years ago and it’s amazing to me how much the world has changed since then. For example, the fifth edition of ECMAScript (ES5) has recently been approved for standardization and it’s already widely implemented in modern browsers, including my favorite browser, IE9.
Fluent LINQ
However, I’m a big C# fan, especially the fluent API style of LINQ methods like Where, Select, OrderBy, etc. As an example, assume the following C# class:
class Person { public Person() { Children = new List<Person>(); } public string Name { get; set; } public DateTime Birthday { get; set; } public int Age { get { return (int)((DateTime.Now - Birthday).Days / 365.25); } } public ICollection<Person> Children { get; private set; } public override string ToString() { return string.Format("{0} ({1})", Name, Age); } }
var chris = new Person() { Name = "Chris", Birthday = new DateTime(1969, 6, 2), Children = { new Person() { Name = "John", Birthday = new DateTime(1994, 5, 5), }, new Person() { Name = "Tom", Birthday = new DateTime(1995, 8, 30), }, }, };
var people = new Person[] { chris }.Union(chris.Children); Console.WriteLine("People: " + people.Aggregate("", (s, p) => s + (s.Length == 0 ? "" : ", ") + p.ToString())); Console.WriteLine("Teens: " + people.Where(p => p.Age > 12 && p.Age < 20). Aggregate("", (s, p) => s + (s.Length == 0 ? "" : ", ") + p.ToString()));
People: Chris (41), John (16), Tom (15) Teens: John (16), Tom (15)
Fluent JavaScript
// Person constructor function Person(args) { if (args.name) { this.name = args.name; } if (args.birthday) { this.birthday = args.birthday; } if (args.children) { this.children = args.children; } } // Person properties and methods Person.prototype = Object.create(null, { name: { value: "", writable: true }, birthday: { value: new Date(), writable: true }, age: { get: function () { return Math.floor((new Date() - this.birthday) / 31557600000); } }, children: { value: [], writable: true }, toString: { value: function () { return this.name + " (" + this.age + ")"; } } });
I can do several LINQ-style things on it:
var s = ""; var tom = new Person({ name: "tom", birthday: new Date(1995, 7, 30) }); var john = new Person({ name: "john", birthday: new Date(1994, 4, 5) }); var chris = new Person({ name: "chris", birthday: new Date(1969, 5, 2), children: [tom, john] }); var people = [tom, john, chris]; // select s += "<h1>people</h1>" + people.map(function (p) { return p; }).join(", "); // where s += "<h1>teenagers</h1>" + people.filter(function (p) { return p.age > 12 && p.age < 20 }).join(", "); // any s += "<h1>any person over the hill?</h1>" + people.some(function (p) { return p.age > 40; }); // aggregate s += "<h1>totalAge</h1>" + people.reduce(function (totalAge, p) { return totalAge += p.age; }, 0); // take s += "<h1>take 2</h1>" + people.slice(0, 2).join(", "); // skip s += "<h1>skip 2</h1>" + people.slice(2).join(", "); // sort s += "<h1>sorted by name</h1>" + people.slice(0).sort( function (lhs, rhs) { return lhs.name.localeCompare(rhs.name); }).join(", "); // dump document.getElementById("output").innerHTML = s;
Notice that several things are similar between JS and C# LINQ-style:
- The array and object initialization syntax looks very similar so long as I follow the JS convention of passing in an anonymous object as a set of constructor parameters.
- The JS Date type is like the .NET DateTime type except that months are zero-based instead of one-based (weird).
- When a Person object is “added” to a string, JS is smart enough to automatically call the toString method.
- The JS map function lets you project from one set to another like LINQ Select.
- The JS filter function lets you filter a set like LINQ Where.
- The JS some function lets you check if anything in a set matches a predicate like LINQ Any.
- The JS reduce function lets you accumulate results from a set like the LINQ Aggregate.
- The JS slice function is a multi-purpose array manipulation function that we’ve used here like LINQ Take and Skip.
- The JS slice function also produces a copy of the array, which is handy when handing off to the JS sort, which acts on the array in-place.
The output looks as you’d expect:

We’re not all there, however. For example, the semantics of the LINQ First method are to stop looking once a match is found. Those semantics are not available in the JS filter method, which checks every element, or the JS some method, which stops once the first matching element is found, but returns a Boolean, not the matching element. Likewise, the semantics for Union and Single are also not available as well as several others that I haven’t tracked down. In fact, there are several JS toolkits available on the internet to provide the entire set of LINQ methods for JS programmers, but I don’t want to duplicate my C# environment, just the set-like thinking that I consider language-agnostic.
So, in the spirit of JS, I added methods to the build in types, like the Array type where all of the set-based intrinsics are available, to add the missing functionality:
Object.defineProperty(Array.prototype, "union", { value: function (rhs) { var rg = this.slice(0); rhs.forEach(function (v) { rg.unshift(v); }) return rg; }}); Object.defineProperty(Array.prototype, "first", { value: function (callback) { for (var i = 0, length = this.length; i < length; ++i) { var value = this[i]; if (callback(value)) { return value; } } return null; }}); Object.defineProperty(Array.prototype, "single", { value: function (callback) { var result = null; this.forEach(function (v) { if (callback(v)) { if (result != null) { throw "more than one result"; } result = v; } }); return result; }});
These aren’t perfectly inline with all of the semantics of the built-in methods, but they give you a flavor of how you can extend the prototype, which ends up feeling like adding extension methods in C#.
The reason to add methods to the Array prototype is that it makes it easier to continue to chain calls together in the fluent style that started all this experimentation, e.g.
// union s += "<h1>chris's family</h1>" +
[chris].union(chris.children).map(function (p) { return p; }).join(", ");
Where Are We?
If you’re a JS programmer, it may be that you appreciate using it like a scripting language and so none of this “set-based” nonsense is important to you. That’s OK. JS is for everyone.
If you’re a C# programmer, you might dismiss JS as a “toy” language and turn your nose up at it. This would be a mistake. JS has a combination of ease-of-use for the non-programmer-programmer and raw power for the programmer-programmer that makes it worth taking seriously. Plus, with it’s popularity on the web, it’s hard to ignore.
If you’re a functional programmer, you look at all this set-based programming and say, “Duh. What took you so long?”
Me, I’m just happy I can program the way I like to in my new home on the web. : )
Saturday, Dec 11, 2010, 3:52 PM in Tools
Using LINQPad to Run My Life: Budgeting
I use LINQPad all the time for a bunch of stuff, but most recently and most relevant, I’ve been using it for a personal chore that isn’t developer-related: I’ve been using it to do budgeting.
What is LINQPad?
LINQPad is an interactive execution environment for LINQ queries, statements or programs. The typical usage model is that you point LINQPad at a SQL database or an OData endpoint via a dialog box and then start writing queries against the tables/collections exposed by that connection, e.g.

Here, you can see that I’ve added a connection on the left to the Northwind database, typed a query into the text box (I paid the $25 for the auto-completion module), executed the query and got the table of results below. If I want to operator over multiple results, including dumping them for inspection, I can do so by switch from C# Expression to C# Statements:

Notice the use of “Dump” to see results along the way. If I want to, I can switch to C# Program, which gives me a main and allows me to create my own types and methods, all of which can be executed dynamically.
To save queries, notice the “My Queries” tab in the lower left. I use this for things I run periodically, like the ads on my web site that are going to expire, some data cleanup I want to get back to and, the subject of today: budgeting.
Budgeting with Mint.com and LINQPad
For the uninitiated, mint.com is a free online personal financial management site. At its core, it uses financial account, loan and asset information that lets it log into various financial sites and grab my data for me, e.g. 1sttech.com, usbank.com, wcb.com, etc. It uses this to let me categorize transactions so that it can do budgeting for me. However, it doesn’t give me the control I want, so I write programs against this unified transaction information. Essentially, I re-categorize each transaction to my own set using a map I maintain in an Excel file, then compare the amount I spend each month against what my budget amount is, maintained in another sheet in that same Excel file. Because mint.com doesn’t provide a programmatic API (OData would be a godsend!), I pull down my transaction history as a CSV file that the web site provides for me, which I then translate to an Excel file.
Once I have these three Excel sheets, the translation history, the category map and the category budget amounts, I bring these pieces of data into my LINQPad script:
void Main() { var mintExcel = ExcelProvider.Create(@"D:\data\finances\2010-08-25 mint transactions.xlsx"); var minDate = new DateTime(2010, 8, 1); var txs = mintExcel.GetSheet<Tx>().Where(t=>t.Date>=minDate); var debits = txs.Where(tx => tx.Type == "debit"); var classExcel = ExcelProvider.Create(@"d:\data\finances\2010-08-03 mint category map.xlsx"); var map = classExcel.GetSheet<CategoryClass>().ToList(); var classBudget = classExcel.GetSheet<ClassBudget>().ToList(); var unclassified = new ClassBudget() { Class = "UNCLASSIFIED" }; classBudget.Add(unclassified); var classifiedDebits = debits. Select(d => new { d.Date, d.Description, Amount = d.Amount, d.Category, Class = GetClass(map, d) }). Where(d => d.Class != null); // TODO: break this down by month // TODO: sum this by ytd var classifiedTotals = from d in classifiedDebits group d by d.Class into g let b = classBudget.FirstOrDefault(b=>b.Class == g.Key) ?? unclassified let total = g.Sum(d=>d.Amount) select new { Class = b.Class, BudgetAmount = b.Amount, ActualAmount = total, AmountLeft = b.Amount - total, TxCount = g.Count(), Transactions = from tx in g.OrderBy(tx=>tx.Date) select new { Date = tx.Date.ToString("M/d/yy"), tx.Description, tx.Category, tx.Amount } }; classifiedTotals.OrderBy(d=>d.Class).Dump(2); //classifiedTotals.OrderBy(d=>d.Class).Dump(); } static string GetClass(List<CategoryClass> map, Tx tx) { CategoryClass cc = map.FirstOrDefault(m => m.Category == tx.Category); if( cc != null ) { return cc.Class; } tx.Category.Dump("UNCLASSIFIED MINT CATEGORY"); return null; } [ExcelSheet(Name = "transactions(1)")] public class Tx { [ExcelColumn()] public DateTime Date { get; set; } [ExcelColumn()] public string Description { get; set; } [ExcelColumn()] public decimal Amount { get; set; } [ExcelColumn(Name = "Transaction Type")] public string Type { get; set; } [ExcelColumn()] public string Category { get; set; } [ExcelColumn(Name = "Account Name")] public string AccountName { get; set; } } [ExcelSheet(Name = "Sheet1")] public class CategoryClass { [ExcelColumn()] public string Category { get; set; } [ExcelColumn(Name="Classification")] public string Class { get; set; } } [ExcelSheet(Name = "Sheet2")] public class ClassBudget { [ExcelColumn(Name="Classification")] public string Class { get; set; } [ExcelColumn()] public decimal Amount { get; set; } public int Transactions { get; set; } }
There are some interesting things to notice about this script:
- I needed to make it a full-fledged program so that I could define the shape of my data in Excel. LINQPad has no native support for Excel data, so I had modify an Excel LINQ provider I found on the interwebtubes. The types are needed to map the Excel columns to C# types so that I can query against them.
- This script isn’t pretty; it’s been built up over time and it works. I’ve been using it for a month and this month my task is to split it work across multiple months.
- I’ve built up error output over time to make sure I’m not dropping data in my queries. I spent an hour a coupla weeks ago tracking down 3 transactions.
- I’m doing slow look-ups cuz at the time I wrote this script, I wasn’t sure how to write joins in LINQ. It’s more than fast enough for my needs, so I’ve only dug into LINQ for accuracy, not efficiency.
LINQPad Output
By default, the output from my budgeting program looks like this (w/ my personal financial details blacked out):

Some things to notice:
- The output is spit into a table w/o me having to do anything except dump the data.
- The number columns have an automatic bar graph glyph on them that shows proportions when clicked.
- The number columns are automatically totally.
- The Transactions column is turned off because I said “Dump(2)”, which only dumps to the 2nd level. By default it would drill down further, e.g.

Bringing in Excel
To bring my Excel data into LINQPad, which supports LINQ to SQL, EF and OData natively but not Excel, I have to right-click on the design surface, choose query properties and tell it about where the source code and namespace is that defines the Excel LINQ Query Provider:


Impressions
The thing that makes this app really work for me is the REPL nature. It’s very immediate and I can see where my money is going with very little ceremony. It’s really the intelligence of the Dump command that keeps me from moving this app to WPF. Dump gives me the view I need to understand where my money goes and it gives me the programming surface to slice/dice the data the way I want to. I have no control out of the box in WPF that’s even close to as useful.
However, Even though I could extend LINQPad myself, there is no integrated support for Excel or CSV files. Further, for some stupid reason, I have to load the files into a running instance of Excel for them to load in LINQPad, which pisses me off because the error messages are ridiculous. Also, there is no intrinsic support for multiple data sources; instead I need to build that myself.
Further, I had one case where I couldn’t figure out an error (it was that I forgot to load the data into Excel) and had to have a real debugger, which LINQPad didn’t have. The good news was that I was able to copy/paste my code into a console application and debug it, but the bad news was that I really missed the Dump command when I was running inside Visual Studio.
Where Are We?
I really love LINQPad. In fact, I find myself wanting the same functionality for other uses, e.g. SQL (real SQL), JavaScript and as a shell. It’s the interactive data access that makes it for me – munge some data, look at it, repeat. It doesn’t quite do everything I want, though – where’s the full-featured, all-data, Swiss army knife for data?
Friday, Oct 29, 2010, 5:10 PM
Management vs. Motivation
“If you want to build a ship, don’t drum up people to gather wood, divide the work, and give them orders. Instead, teach them to yearn for the vast and endless sea."
Antoine De Saint-Exupery, author of "The Little Prince"
Wednesday, Oct 27, 2010, 6:42 PM in Tools
LINQ Has Changed Me
In the old days, the post-colonial, pre-LINQ days of yore, I’d have written a one-way MD5 encryption like so:
static string GetMD5String(string s) { MD5 md5 = new MD5CryptoServiceProvider(); byte[] hash = md5.ComputeHash(Encoding.ASCII.GetBytes(s)); StringBuilder sb = new StringBuilder(); foreach( byte b in hash ) sb.AppendFormat("{0:x2}", b); return sb.ToString(); }
This implementation is fine and has served me well for 10 years (I pulled it out of the first .NET project I ever really did). However, after using LINQ for so long, it’s hard not to see every problem as an operation over sets:
static string GetMD5String(string s) { return (new MD5CryptoServiceProvider()). ComputeHash(Encoding.Unicode.GetBytes(s)). Aggregate(new StringBuilder(), (working, b) => working.AppendFormat("{0:x2}", b)). ToString(); }
I can’t say that the LINQ version is any better, but it felt better. However, you’ll notice that I’m not using any of the LINQ keywords, e.g. “select”, “where”, etc. I find that I don’t really use them that much. It’s too jarring to mix them, e.g. “(from f in foos select f).Take(3)”, since not everything has a LINQ keyword equivalent. I tend to do “LINQ-less LINQ” more often then not.
P.S. I assume someone will be able to tell me how I can do it better. : )
P.P.S. I’m using the Insert Code for Windows Live Writer add-in. I love WLW!
Wednesday, Oct 27, 2010, 1:48 PM in The Spout
A Function That Forces
 At Microsoft, there’s this passive-aggressive cultural thing called a “forcing function,” which, to put it crudely, is an engineering way for us to control the behavior of others. The idea is that you set up something to happen, like a meeting or an event, that will “force” a person or group to do something that you want them to do.
At Microsoft, there’s this passive-aggressive cultural thing called a “forcing function,” which, to put it crudely, is an engineering way for us to control the behavior of others. The idea is that you set up something to happen, like a meeting or an event, that will “force” a person or group to do something that you want them to do.
For example, if someone won’t answer your email, you can set up a meeting on their calendar. Since Microsoft is a meeting-oriented culture (even though we all hate them), a ‘softie will be very reticent to decline your meeting request. So, they have a choice – they can attend your meeting so that they can answer your question in person or they can answer your email and get that time back in their lives. This kind of forcing function can take larger forms as well. I can’t say that our execs make the decision like this (since they don’t talk to me : ), but it is the case that signing up a large number of Microsoft employees to host and speak at important industry events does have the effect of making us get together to ensure that our technologies and our descriptions of those technologies holds together (well, holds together better than they would otherwise : ).
Unfortunately, this way of thinking has become so much a part of me that I’ve started to use it on my family (which they very much do not like). Worse, I use it on myself.
For example, I have been holding back on half a dozen or more blog posts until I have the software set up on my newly minted web site to handle blog posts in a modern way, namely via Windows Live Writer. In other words, I was using the pressure inherent in the build up of blogging topics to motivate me to build the support I wanted into sellsbrothers.com to have a secure blogging endpoint for WLW. Before I moved all my content into a database, I could just pull up FrontPage/Expression Web and type into static HTML. Now that everything is data-driven, however, the content for my posts are just rows in a database. As much as I love SQL Server Management Studio, it doesn’t yet have HTML editing support that I consider adequate. Further, getting images into my database was very definitely a programming task not handled by existing tools that I was familiar with.
So, this is the first post using my new WLW support and I’m damn proud of it. It was work that I did with Kent Sharkey, a close friend of mine that most resembles Eeyore in temperament and facial expressions, and that just made it all the more fun!
Anyway, I’m happy with the results of my forcing function and I’ll post the code and all the details ASAP, but I just wanted to apologize for my relative silence on this blog and that things should get better RSN. XXOO.
P.S. I’m loving Windows Live Writer 11!
Monday, Oct 25, 2010, 11:30 PM in Conference
Data at PDC 2010
There are lots of great data talks at PDC 2010, all of which are available for online viewing:
- Code First Development with Entity Framework
Jeff Derstadt, Tim Laverty
Thursday, 2:00 PM-3:00 PM (GMT-7)
- Creating Custom OData Services: Inside Some of The Top OData Services
Pablo Castro
Thursday, 3:15 PM-4:15 PM (GMT-7)
- Enabling New Scenarios and Applications with Data in the Cloud
Dave Campbell
Thursday, 4:30 PM-5:30 PM (GMT-7)
- Building Scale-Out Database Solutions on SQL Azure
Lev Novik
Friday, 2:00 PM-3:00 PM (GMT-7)
- Building Offline Applications using the Sync Framework and SQL Azure
Nina Hu
On Demand
Enjoy!
Monday, Sep 27, 2010, 4:50 PM in Tools
Time to check the donuts
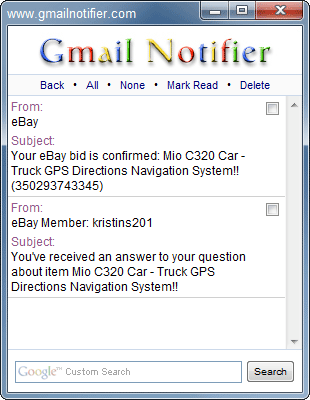
One day when I was supposed to be writing, I needed something to do (as often happens). In this particular case, I built a little tray icon app using the new (at the time) tray icon support in Windows Forms (this was a while ago : ). The data I was checking was my gmail account and whenever there was new mail, I'd pop up a notification. All very simple, so to be funny, instead of saying "You've got mail,"� my program said "I's time to check the donuts."
Over time, I came to rely on this app but lamented the lack of features, like seeing who the email was from or marking an email as read w/o logging in, etc. Over time, I came to wish I had something like Gmail Notifier. I's free and while it doesn't contain an '80s commercial reference, it has way more features than I ever built into mine. Oh, and the noise it makes when you get an email is priceless. Recommended.
Thursday, Aug 26, 2010, 7:12 AM in Fun
The Downside Of Working At Home

I've been working at home off and (mostly) on for 16 years...
From theoatmeal.com. Recommended!
Sunday, Aug 8, 2010, 8:19 AM in The Spout
Why can't it all just be messages?
My mobile device is driving me crazy.
I have an iPhone 4.0. Normally when it's driving me crazy, it's standard stuff like the battery life sucks or that the iOS 4.0.1 update didn't fix the proximity detection or stop emails I send via Exchange from just disappearing into the ether.
This time, it's something else and I can't blame the iPhone; I think all modern smart phones have the same problem. The problem is that I constantly have to switch between apps to see my messages. Here are screenshots for 5 of the messaging clients I use reguarly:
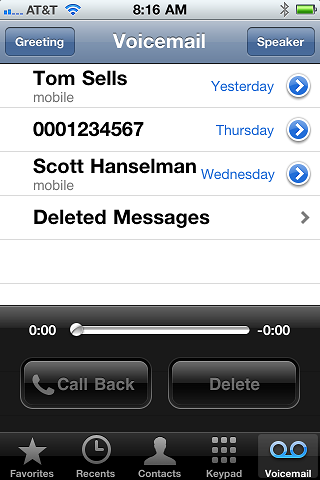
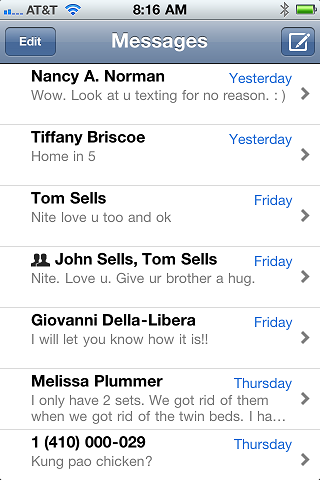
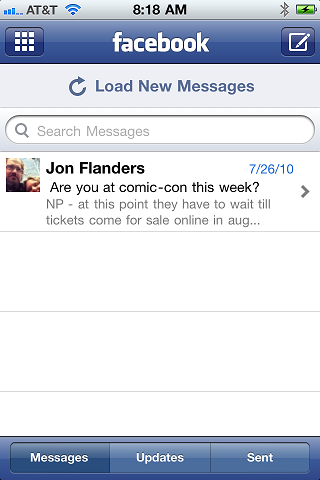
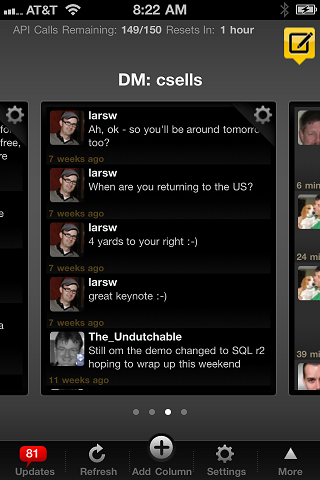
This list doesn't include real-time messages like IM, or notifications like Twitter or RSS. I'm just talking about plain ol' async messaging. We used to think of it as "email," but really voicemail, email, SMS, MMS, Facebook messages and Twitter Direct Messages are all the same -- they are meant to queue up until you get to them.
Now, some folks would argue that SMS/MMS aren't meant to be queued; they're meant to be seen and handled immediately. Personally, I find it annoying that there is a pop-up for every single text or media messages I get on my phone and there seems to be no way to turn that off. On the other hand, if I want that to happen for other types of messages, e.g. voicemail, I can find no way to turn it on even if I want to. Why are text messages special, especially since most mobile clients let you get over the 160 character limit and will just send them one after the other for you anyway?
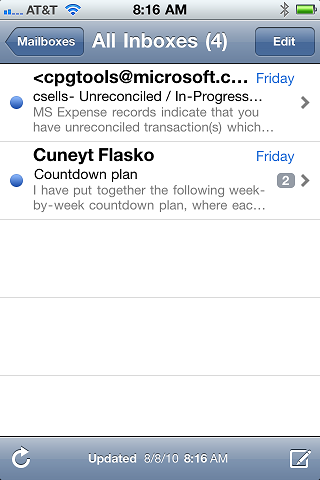
iOS 4 takes a step in the right direction with the "universal" inbox:
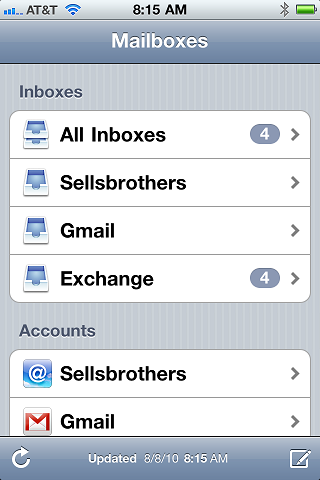
Here I've got a great UI for getting to all my email messages at once, but why can't it handle all my messages instead?
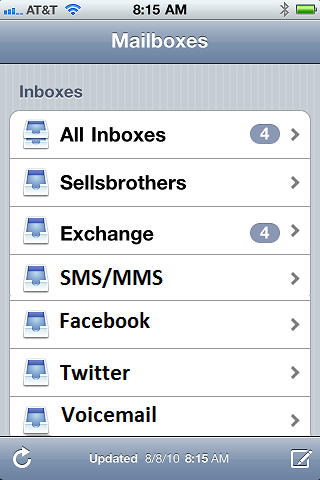
Not only would this put all my messages in one place at one time, but it would unify up the UI and preferences across the various messaging sources. Do you want your text messages to quietly queue up like email? Done. Do you want your voicemail to pop to the front like an SMS? Done. Do you want the same swipe-to-delete gestures on your voicemail as you have with your email? Done!
Maybe someone with some experience on the new Windows Phone 7 can tell me that there is a "messaging" hub that manages all this for me. Since they're already doing things like bringing facebook pictures into the "pictures" hub (or whatever they call it), that doesn't seem completely out of the realm of possibility. If that's the case, I'll say again what I've been saying for a while -- I can't wait for my Windows Phone 7!
Friday, Jun 18, 2010, 11:43 AM in Interview
David Ramel Asks About Interviewing at Microsoft
David Ramel from 1105media.com is writing an article that includes the Microsoft interviewing process and he send me some questions:
[David] How would you succinctly sum up the Microsoft interview process as compared to those of other tech companies?
[Chris] MS does some things similarly to other high-tech companies I've worked with, e.g. having each interviewer focus on an aspect or aspects, e.g. team skills, people skills, technical skills, etc., expecting a candidate to ask questions, communicating between interviewers to push more on one area or another, etc. The riddle questions are a uniqueness at Microsoft (at least they were when I last interviewed), but theyire pretty rare these days. Coding on the whiteboard also seems pretty unique to Microsoft (myself, I prefer the keyboard : ).
[David] How has the Microsoft interview process changed over time? (Microsoft seems to have shaken up the tech interview process some years ago with those brain-teasing puzzle� questions, but now seem to be much more technically-oriented and job-specific. Just wondering about your thoughts on this observation.)
[Chris] While I have had them, puzzle questions were rare even when I was interviewed 7 years ago. Since then, I haven't run into many people that use them. However, when they are used, an interviewer is often looking for how a candidate works through an issue as much as the solution that they come up with. In an ever changing world, being able to learn and adapt quickly is a huge part of how successfully you can be in the tech industry at all and at Microsoft specifically. I prefer technical design questions for these kinds of results, however, and it seems that most 'softies agree.
[David] What would you say was the biggest factor in your being offered a job at Microsoft?
[Chris] I had a reputation outside of MS before I interviewed, but that almost didn't matter. If I hadn't done well during the interview, I would not have been offered the job. When in doubt, a team generally prefers to turn away a good candidate rather than to risk taking on a bad one, so if there's anything wrong, team fit, technical ability, role fit, etc., a candidate won't get an offer.
[David] What's the single most important piece of advice you can offer to those preparing for a Microsoft job interview?
[Chris] You asked for just one, but I'm going to give you two anyway. : )
- If you need more information to answer a question, ask for it. Thatis how the real-world works and many questions are intentionally vague to simulate just this kind of interaction.
- Try to answer non-technical questions based on your personal experience, e.g. instead of saying "here's how I would deal with that situation,"� say "I had a similar situation in my past and hereis how I dealt with it."� This is a style of interviewing known as behavioral� and even if your interviewer doesn't phrase his questions in that way, e.g. "give me an example of how you dealt with a situation like blah,"� it's helpful and impressive if you can use your own history to pull out a positive result.
[David] Could you please share any other observations you have on the Microsoft interview process that may not be covered in your site or the Jobsblog?
[Chris] I run a little section of my web site dedicated to the MS interviewing process and the thing I will tell you is this: don't prepare. Be yourself. If you're not a fit for MS, no amount of preparation in the days before an interview will help and if you are a fit, that will come through in the interview. Also, make sure you ask questions. Working at Microsoft isn't just a job, it's a way of life, so make sure you're sure you want the team and the job for which you're interviewing.
[David] Does MS provide training for interviewers? If so, what do they stress most?
[Chris] I'm sure MS does provide training for interviewing, but Iive never been to it. At Intel, I learned the behavioral interviewing technique, which Iive used in every interview since, both as an interviewer and as a job candidate.
[David] Do you have standard questions, or do you tailor them to the situation? If the latter, is it usually tailored for team fit, to a specific open position, particular skills, etc.?
[Chris] I have once standard technique question and a few standard behavioral interview questions. The technical question is to ask them what their favorite technology is and/or what they consider themselves to be an expert� in and then drill in on their understanding. If they can answer my questions deeply, this shows passion about technology and the ability to learn something well, both of which are crucial for success at MS.
My behavioral interviewing questions are things like "Tell me about a time when youive been in conflict with a peer. How did you resolve it? What was the result? What did you learn?"� and "Tell me about a time when you had much too much work to do in the time you were given. How do you resolve that issue? What was the result? What did you learn?"� The core idea of behavioral interviewing is that past behavior indicates future behavior, so instead of asking people things like "How would you deal with such-and-such?�" you ask them "How did you dealt with such-and-such in the past?"� This forces them to find a matching scenario and you get to see if they way they dealt with the issue in real life matches what you want from a team mate in that job.
[David] How would you describe the kinds of coding questions you ask? A couple of real examples would be perfect!
[Chris] I don't often ask coding questions, but when I have, I let them use a keyboard. I hate coding on the board myself as it's not representative of how people actually code, so I don't find it to be a good indicator of what people will actually do. I guess I even use behavioral techniques for technical questions, now that I think about it. : )
Sunday, May 23, 2010, 8:40 PM in .NET
Spurious MachineToApplication Error With VS2010 Deployment

Often when I'm building my MVC 2 application using Visual Studio 2010, I get the following error:
It is an error to use a section registered as allowDefinition='MachineToApplication' beyond application level. This error can be caused by a virtual directory not being configured as an application in IIS.
On the internet, this error seems to be related to having a nested web.config in your application. I do have such a thing, but it's just the one that came out of the MVC 2 project item template and I haven't touched it.
In my case, this error in my case doesn't seem to have anything to do with a nested web.config. This error only started to happen when I began using the web site deployment features in VS2010 which by itself, rocks (see Scott Hanselman's "Web Deployment Made Awesome: If You're Using XCopy, You're Doing It Wrong" for details).
If it happens to you and it doesn't seem to make any sense, you can try to fix it with a Build Clean command. If you're using to previous versions of Visual Studio, you'll be surprised, like I was, not to find a Clean option in sparse the Build menu. Instead, you can only get to it by right-clicking on your project in the Solution Explorer and choosing Clean.
Doing that, however, seems to make the error go away. I don't think that's a problem with my app; I think that's a problem with VS2010.
Thursday, May 20, 2010, 6:11 PM in Colophon
a whole new sellsbrothers.com
![]()
The new sellsbrothers.com implementation has been a while in the making. In fact, I've had the final art in my hands since August of 2005. I've tried several times to sit down and rebuild my 15-year-old sellsbrothers.com completely from scratch using the latest tools. This time, I had a book contract ("Programming Data," Addison-Wesley, 2010) and I needed some real-world experience with Entity Framework 4.0 and OData, so I fired up Visual Studio 2010 a coupla months ago and went to town.
The Data Modeling
The first thing I did was design my data model. I started very small with just Post and Comment. That was enough to get most of my content in. And that lead to my first principle (we all need principles):
thou shalt have no .html files served from the file system.
On my old site, I had a mix of static and dynamic content which lead to all kinds of trouble. This time, the HTML at least was going to be all dynamic. So, once I had my model defined, I had to import all of my static data into my live system. For that, I needed a tool to parse the static HTML and pull out structured data. Luckily, Phil Haack came to my rescue here.
Before he was a Microsoft employee in charge of MVC, Phil was well-known author of the SubText open source CMS project. A few years ago, in one of my aborted attempts to get my site into a reasonable state (it has evolved from a single static text file into a mish-mash of static and dynamic content over 15 years), I asked Phil to help me get my site moved over to SubText. To help me out, he built the tool that parsed my static HTML, transforming the data into the SubText database format. For this, all I had to do was transform the data from his format into mine, but before I could do that, I had to hook my schema up to a real-live datastore. I didn't want to have to take old web site down at all; I wanted to have both sites up and running at the same time. This lead to principle #2:
thou shalt keep both web sites running with the existing live set of data.
And, in fact, that's what happened. For many weeks while I was building my new web site, I was dumping static data into the live database. However, since my old web site sorting things by date, there was only one place to even see this old data being put in (the /news/archive.aspx page). Otherwise, it was all imperceptible.
To make this happen, I had to map my new data model onto my existing data. I could do this in one of two ways:
- I could create the new schema on my ISP-hosted SQL Server 2008 database (securewebs.com rocks, btw -- highly recommended!) and move the data over.
- I could use my existing schema and just map it on the client-side using the wonder and beauty that was EF4.
Since I was trying to get real-world experience with our data stack, I tried to use the tools and processes that a real-world developer has and they often don't get to change the database without a real need, especially on a running system. So, I went with option #2.
And I'm so glad I did. It worked really, really well to change names and select fields I cared about or didn't care about all from the client-side without ever touching the database. Sometimes I had to make database changes and when that happened, I has careful and deliberate, making the case to my inner DB administrator, but mostly I just didn't have to.
And when I needed whole new tables of data, that lead to another principle:
build out all new tables in my development environment first.
This way, I could make sure they worked in my new environment and could refactor to my heart's content before disturbing my (inner) DB admin with request after request to change a live, running database. I used a very simple repository pattern in my MVC2 web site to hide the fact that I was actually accessing two databases, so when I switched everything to a single database, none of my view or controller code had to change. Beautiful!
Data Wants To Be Clean
And even though I was careful to keep my schema the same on the backend and map it as I wanted in my new web site via EF, not all of my old data worked in my new world. For example, I was building a web site on my local box, so anything with a hard-coded link to sellsbrothers.com had to be changed. Also, I was using a set of <a name="tag" ? elements to reference specific posts in my static HTML that just didn't scale to my dynamic ID-based permalinks, so data had to be "cleaned."
To do this cleaning, I used a combination of LINQPad, SSMS and EF-based C# code to perform data cleaning tasks. This yielded two tools that I'm still using:
- BlogEdit: An unimagintively named general-purpose post and comment creation and editing tool. I built the first version of this long before WPF, so kept hacking on it in WinForms (whose data binding sucks compared to WPF, btw) as I needed it to have new features. Eventually I gave this tool WYSIWIG HTML editing by shelling out to Expression Web, but I need real AtomPub support on the site so I can move to Windows Live Writer for that functionality in the future.
- BulkChangeDatabaseTable: This was an app that I'd use to run my questions to find "dirty" data, perform regular expression replaces with and then -- and this is the best part -- show the changes in WinDiff so I could make sure I was happy with the changes before commiting them to the database. This extra eyeballing saved me from wrecking a bunch of data.
During this data cleaning, I applied one simple rule that I adopted early and always regretted when I ignored:
thou shalt throw away no data.
Even if the data didn't seem to have any use in the new world, I kept it. And it's a good thing I did, because I always, always needed it.
For example, when I ran Phil's tool to parse my static web pages, he pulled out the <a name="tag" /> tags that went with all of my static posts. I wasn't going to use them to build permalinks, why did I need them?
I'll tell you why: because I've got 2600 posts in my blog from 15 years of doing this, I cross-link to my own content all the live-long day and a bunch of those cross-links are to, you guessed it, to what used to be static data. So, I have to turn links embedded in my content of the form "/writing/#footag" into links of the form "/posts/details/452". But how do I look up the mapping between "footag" and "452"? That's right -- I actually went to my (inner) DB admin and begged him for a new column on my live database called "EntryName" where I tucked the <a name="tag" /> data as I imported the data from Phil's tool, even though I didn't know why I might need it. It was a good principle.
Forwarding Old Links
And how did I even figure out I had all those broken links? Well, I asked my good friend and web expert Kent Sharkey how to make sure my site was at least internally consist before I shipped it and he recommended Xenu Link Sleuth for the job. This lead to another principle:
thou shalt ship the new site with no broken internal links.
Which was followed closely by another principle:
thou shalt not stress over broken links to external content.
Just because I'm completely anal about making sure every link I ever pass out to the world stays valid for all eternity doesn't mean that the rest of the world is similiarly anal. That's a shame, but there's nothing I can do if little sites like microsoft.com decide to move things without a forwarding address. I can, however, make sure that all of my links worked internally and I used Xenu to do that. I started out with several hundred broken links and before I shipped the new site, I had zero.
Not all of that was changing old content, however. In fact, most of it wasn't. Because I wanted existing external links out in the world to find the same content in the new place, I had to make sure the old links still worked. That's not to say I was a slave to the old URL format, however. I didn't want to expose .aspx extensions. I wanted to do things the new, cool, MVC way, i.e. instead of /news/showTopic.aspx?ixTopic=452 (my old format), I wanted /posts/details/452. So, this lead to a new principle:
thou shalt built the new web site the way you want and make the old URLs work externally.
I was using MVC and I wanted to do it right. That meant laying out the "URL space" the way it made sense in the new world (and it's much nicer in general, imo). However, instead of changing my content to use this new URL schema, I used it as a representative sample of how links to my content in the real-world might be coming into my site, which gave me initial data about what URLs I needed to forward. Ongoing, I'll dig through 404 logs to find the rest and make those URLs work appropriately.
I used a few means of forwarding the old URLs:
- Mapping sub-folders to categories: In the old site, I physically had the files in folders that matched the sub-folders, e.g. /fun mapped to /fun/default.aspx. In the new world, /fun meant /posts/details/?category=fun. This sub-folder thing only works for the set of well-defined categories on the site (all of which are entries in the database, of course), but if you want to do sub-string search across categories on my site you can, e.g. /posts/details/?category=foo.
- Kept sub-folder URLs, e.g. /tinysells and /writing: I still liked these URLs, so I kept them and built controllers to handle them.
- Using the IIS URL Rewriter: This was the big gun. Jon Galloway, who was invaluable in this work, turned me onto it and I'm glad he did. The URL Rewriter is a small, simple add-in to IIS7 that lets you describe patterns and rules for forwarding when those patterns are matched. I have something like a dozen patterns that do the work to forward 100s of URLs that are in my own content and might be out in the world. And it works so, so well. Highly recommended.
So, with a combination of data cleaning to make my content work across both the old site and the new site under development, making some of my old URLs work because of conventions I adopted that I wanted to keep and URL rewriting, I had a simple, feature-complete, 100% data-driven re-implementation of sellsbrothers.com.
What's New?
Of course, I couldn't just reimplement the site without doing something new:
- Way, way faster. SQL Server 2008 and EF4 make the site noticibly faster. I love it. Surfing from my box, as soon as the browser window is visible, I'm looking at the content on my site. What's better than that?
- I made tinysells.com work again, e.g. tinysells.com/42. I broke when I moved it from simpleurl.com to godaddy.com. Luckily, godaddy.com was just forwarding to sellsbrothers.com/tinysells/<code>, so that was easy to implement with a MVC controller. That was all data I already had in the database because John Elliot, another helper I had on the site a while ago, set it up for me.
- I added reCAPTCHA support: Now I'm hoping I won't have to moderate comments at all. So far, so good. Also, I added the ability to add HTML content, which is encoded, so it comes right back the way it went in, i.e. no action scripts or links or anything a spammer would want but the characters a coder wants putting content into a technical blog.
- Per category ATOM and OData feeds (and RSS feeds, too, if you care). For example, if you click on the ATOM or OData icons on the home page, you'll get the feed for everything. However, if you click on it on one of the category pages, e.g. /fun, you'll get a feed filtered by category.
- Paging in OData and HTML: This lets you scroll to the bottom of both the OData feed and the HTML page to scroll backwards and forwards in time.
- New layout including fixed-sized content area for readability, google ads and bing search (I'd happily replace google ads with bing ads if they'd let me).
- Nearly every sub-page is category driven, although even the ones that aren't, e.g. /tinysells and /writing and still completely data-driven. Further, the writing page is so data-driven that if the data is just an ISDN, it creates an ASIN associate ID for amazon.com. Buy those books, people! : )
The Room for Improvement
As always, there's a long list of things I wish I had time to do:
- The way I handle layout is with tables 'cuz I couldn't figure out how to make CSS do what I wanted. I'd love expert help!
- Space preservation in comments so code is formatted correctly. I don't actually know the right way to go about this.
- Blog Conversations: The idea here is to let folks put their email on a forum comment so that when someone else comments, they're notified. This happens on forums and Facebook now and I like it for maintaining a conversation over time.
- In spite of my principle, I didn't get 100% of the HTML content on the site into the database. Some of the older, obscure stuff is still in HTML. It's still reachable, but I haven't motivated myself to get every last scrap. I will.
- I can easily expose more via OData. I can't think why not to and who knows what folks might want to do with the data.
- I could make the site a little more readable on mobile devices.
- I really need full support for AtomPub so I can use Windows Live Writer.
- I'd like to add the name of the article into the URL (apparently search engines like that kind of thing : ).
- Pulling book covers on the writing page from the ISBN number would liven up the joint, I think.
- Pass the SEO Toolkit check. (I'm not so great just now.)
Luckily, with the infrastructure I've got in place now, laying in these features over time will be easy, which was the whole point of doing this work in the first place.
Where are we?
All of this brings me back to one more principle. I call it Principle Zero:
thou shalt make everything data-driven.
I'm living the data-driven application dream here, people. When designing my data model and writing my code, I imagined that sellsbrothers.com was but one instance of a class of web applications and I kept all of the content, down to my name and email address, in the database. If I found myself putting data into the code, I figured out where it belonged in the database instead.
This lead to all kinds of real-world uses of the database features of Visual Studio, including EF, OData, Database projects, SQL execution, live table-based data editing, etc. I lived the data-driven dream and it yielded a web site that's much faster and runs on much less code:
- Old site:
- 191 .aspx file, 286 KB
- 400 .cs file, 511 KB
- New site:
- 14 .aspx files, 19 KB
- 34 .cs files, 80 KB
Do the math and that's 100+% of the content and functionality for 10% of the code. I knew I wanted to do it to gain experience with our end-to-end data stack story. I had no idea I would love it so much.
Tuesday, May 11, 2010, 3:53 PM in Data
Entity Framework 4.0 POCO Classes and Data Services
If you've flipped on the POCO (Plain Ol' CLR Objects) code generation T4 templates for Entity Framework to enable testing or just 'cuz you like the code better, you might find that you lack the ability to expose that same model via Data Services as OData (Open Data). If you surf to the feed, you'll likely see something like this:
The XML page cannot be displayed
Cannot view XML input using XSL style sheet. Please correct the error and then click the Refresh button, or try again later.
The following tags were not closed: feed. Error processing resource 'http://localhost:10749/MyODataEndpoint.svc/Posts'
There are two problems. The first problem is that we're not reporting the problem very well. You can't see what's happening in IE8 with a simple View Source, as apparently IE won't show malformed XML. Instead, you have to use Fiddler or some other tool (I'm a big tcpTrace fan) to see the actual error in the HTTP response:
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <feed ...> <title type="text">Posts</title> <id>http://localhost:8080/MyODataEndpoint.svc/Posts</id> <updated>2010-05-11T22:48:13Z</updated> <link rel="self" title="Posts" href="Posts" /> <m:error> <m:code></m:code> <m:message xml:lang="en-US">Internal Server Error. The type 'System.Data.Entity.DynamicProxies.Post_CF2ABE5AD0B93AE51D470C9FDFD72E780956A6FD7294E0B4205C6324E1053422' is not a complex type or an entity type.</m:message> </m:error>
It's in the creation of the OData feed that the error happens, so instead of clearing the response and just returning the error, we dump it into the middle of the output, making it very difficult to find. In this case, what we're telling you is that you've mistakenly left dynamic proxy creation on, which doesn't work with EF4 POCO objects and Data Services in .NET 4.0. To fix this, you need to override the CreateDataSource method in your DataService<T> derived class:
public class MyODataEndpoint : DataService<FooEntities> {
public static void InitializeService(DataServiceConfiguration config) {
...
}
protected override sellsbrothersEntities CreateDataSource() {
var dataSource = new FooEntities();
dataSource.ContextOptions.ProxyCreationEnabled = false;
return dataSource;
}
}
This solution came from Shyam Pather, a Dev Manager on the EF team. He says that once you turn off proxy generation, you give up lazy loading and "immediate" change tracking. Instead, you'll get "snapshot" change tracking, which means the context won't be informed when the properites are changed, but the context still detects changes when you call DetectChanges() or SaveChanges(). For the internals of a Data Service, none of this matters, but any code you write in query interceptors, change interceptors, or service operations will have to be aware of this.
This limitations are only true when used from the OData endpoint, of course. The rest of your app will get proxy creation by default unless you turn it off.
Friday, May 7, 2010, 3:40 PM in Fun
Working Hard: WhirlyBall
What my team does on an average Wednesday afternoon:
It was surprisingly fun.
Thursday, May 6, 2010, 11:41 AM
We're taking OData on the Road!
We have a series of free, day-long events we're doing around the world to show off the beauty and wonder that is the Open Data Protocol. In the morning we'll be showing you OData and in the afternoon we'll help you get your OData services up and running. Come one, come all!
- New York, NY - May 12, 2010
- Chicago, IL - May 14, 2010
- Mountain View, CA - May 18, 2010
- Shanghai, China - June 1, 2010
- Tokyo, Japan - June 3, 2010
- Reading, United Kingdom - June 15, 2010
- Paris, France - June 17, 2010
Your speakers are going to include Doug Purdy, so book now. Spots are going to go fast!